
![]()
Yes, you really can run a virtual conference using only open source tools.
The Fedora Design Team discovered this first-hand hosting the very first Creative Freedom Summit in January, 2023. Using open source tools for running a virtual conference can be quite effective.
In this article, I’ll share with you some of the background of our conference, why using open source tools to run the conference itself was important to us, and the specific tools and configurations we use to make it all work! We’ll also talk about what worked really well, and what room remains for improvement at our next summit in 2024!
Creative Freedom Summit Background
The Creative Freedom Summit was an idea Marie Nordin came up with coming out of reviewing talk submissions for Flock, the annual Fedora users and contributors conference. For the last Flock in August 2022, she received a lot of talk submissions relating to design and creativity in open source – far more than we could possibly accept! With so many great ideas for open source design related talks out there, she wondered if there would be space for a separate open source creativity conference, focused on creatives who use open source tools to create their work.
Marie brought this idea to the Fedora Design Team in the fall of 2022 and we started planning the conference, which took place January 17- 19, 2023. Since it was our first time running a new conference like this, we decided to start out with invited speakers based on some of the talk submissions and our own personal network of open source creatives. Almost every speaker we invited ended up giving a talk, so we didn’t have room to accept submissions. This is something we will need to figure out next year, so we don’t have an open source CFP (Call for Papers) management tool for that to tell you about, yet!
Using Open Source for Open Source Conferences
Since the initial COVID pandemic lockdowns, Fedora’s Flock conference has been run virtually using Hopin, an online conference platform that isn’t open source but is friendly to open source tools. Fedora started using it some years ago and it definitely provides a professional conference feel, with a built-in sponsor booth / expo hall, tracks, hallway chat conversations, and moderation tools. Running the Creative Freedom Summit using Hopin was an option for us, because as a Fedora-sponsored event, we could get access to Fedora’s Hopin setup. Again, Hopin is not open source.
Now, as a long-term (~20 years) open source contributor, I can tell you that this kind of decision is always a tough one. If your conference is focused on open source, it feels a little strange to use a proprietary platform to host your open source conference. As the scale and complexity of our communities and events has grown, however, the ability to produce an integrated open source conference system has grown more challenging.
There is no right or wrong answer. You have to weigh a lot of things when making this decision:
- budget
- people power
- infrastructure
- technical capability
- complexity / formality / culture of event
We didn’t have any budget for this event. We had a team of volunteers who could put some work hours into the event. We had the Fedora Matrix Server as a piece of supported infrastructure we could bring into the mix, as well as access to a hosted WordPress system we could use for the website. Myself and teammate Madeline Peck had the technical capability / experience running live, weekly Fedora Design Team video calls using PeerTube. We wanted the event to be a low-key, single-track, informal event, so we had some tolerance for glitches or rough edges as we proved it out. We also all had a lot of passion about trying an open source stack!
Now you know a little bit about what we weighed when making this decision for us, which might help when making your own decision for your event.
An Open Source Conference Stack: The Nitty-Gritty
Here is how the conference tech stack worked.
Overview
Live Components
- Live Stream: We streamed the stage and the social events to a PeerTube channel. Conference attendees could watch the stream live from our PeerTube channel. PeerTube includes some privacy-minded analytics to track number of live stream viewers and post-event views.
- Live Stage + Social Event Room: We had one live stage for speakers and hosts, using Jitsi. This ensured only those with permission to be on camera could do so. We had an additional Jitsi meeting room for social events which would allow anyone who wanted to participate in the social event to go on camera.
- Backstage: We had a “Backstage” Matrix channel for the event to coordinate with speakers, hosts, and volunteers in one place while the event was going on.
- Announcements and Q&A: We managed Q&A and the daily schedule for the conference via a shared Etherpad (which we later moved to Hackmd.io.)
- Integrated and Centralized Conference Experience: Using Matrix’s Element client, we embedded the live stream video and an Etherpad into a public Matrix room for the conference. We used attendance in the channel to monitor overall conference attendance. We had live chat going throughout the conference and took questions from audience members both from the chat and the embedded Q&A Etherpad.
- Conference Website: We had a beautifully-designed website created by Ryan Gorley hosted on WordPress which had the basic information and links for how to join the conference, the dates/times and schedule.
Post-Event Components
- Post-Event Survey: We used the open source LimeSurvey system to send out a post-event survey to see how things went for attendees. Some of the data from that survey will be included in this article

- Post-Event Video Editing and Captioning: We didn’t have a live captioning system for the conference, but as I was able, I typed live notes from talks into the channel which was greatly appreciated by attendees. Post-event, we used Kdenlive (one of the tools featured in talks at the event) to edit the videos and generate captions.
- Event Recordings: PeerTube automagically posts live stream recordings to channels if you configure it to, which made having nearly instant recordings available for attendees to access for talks they may have missed.
Let’s talk about some of this in detail!
Live Stream: PeerTube

We used the LinuxRocks PeerTube platform generously hosted by LinuxRocks.online for the Creative Freedom Summit’s live stream. PeerTube is a free and open source decentralized video platform that is also part of the Fediverse.
One of the best features of PeerTube (that other platforms I am aware of don’t have) is that after your live stream ends, you get a near instant replay recording posted to your channel on PeerTube. This was a major advantage of the platform cited by users in our chatroom. If you had to miss a session you were really interested in while attending the Creative Freedom Summit, you could watch it within minutes of that talk’s end. It took no manual intervention, uploading, or coordination on the volunteer organizing team to make this happen: PeerTube automated it for us.
Here is how livestreaming with PeerTube works: You create a new live stream on your channel, and it gives you a livestreaming URL + a key to authorize streaming to the URL. This URL + key can be re-used over and over. As we configured it, as soon as a live stream ended, the recording would be posted to the channel we created the livestreaming URL in. copy/paste into Jitsi when you start the livestream. This means that you don’t have to generate a new URL+key per talk during the conference – the overhead of managing that for organizers would have been pretty inconvenient. Instead, you can just re-use the same URL+key. This meant we could have a common document shared with conference organizers (we each had different shifts hosting talks) with the single URL+key so anyone on the team with access to that document would be able to start the livestream.
How to generate the livestream URL+key in PeerTube
Here is how to generate the livestream URL+key in PeerTube, step-by-step:
1. Create Stream Video on PeerTube
Log into PeerTube, and click the “Publish” button in the upper right corner:

2. Click on the “Go live” tab (fourth from the left) and make sure the following settings are set:
- Channel: (The channel name you want the livestream to publish on)
- Privacy: Public
- Radio buttons: Normal live
Then, click “Go Live” (don’t worry, you won’t really be going live quite yet, there is more data to fill in.)

3. Basic info (don’t click update yet)
First you’ll fill out the “Basic Info” tab, then we’ll do the “Advanced Settings” tab in the next step. You’ll be filling out the name of the live stream, a description of the live stream, adding tags, categories, license, etc. here. One thing to remember:
- Make sure publish after transcoding checkbox is turned on!
This ensures once your livestream ends, the recording will automatically post to your channel.
4. Advanced Settings
This is where you can upload a “standby” image that shows up before the stream goes live, while everyone is watching the stream URL and waiting for things to start.
 This is what we used for the Creative Freedom Summit:
This is what we used for the Creative Freedom Summit:

5. Start Live Stream on PeerTube
Now you can hit the update button in the lower right corner. The stream will appear like this – it’s in a holding pattern until you start streaming from Jitsi:

6. Copy / Paste Live Stream URL for Jitsi
Final step in Peer tube… once you’ve got the livestream up, click on the “…” icon under the video and towards the right:

Select “Display live information.” You’ll get a dialog like this:

You need to copy both the Live RTMP URL as well as the Live stream key. You will combine them into one URL and then copy paste that into Jitsi.
So here’s examples from my test run of these two text blocks to copy:
Live RTMP Url:
rtmp://peertube.linuxrocks.online:1935/live
Live stream key:
8b940f96-c46d-46aa-81a0-701de3c43c8f
What you’ll need to paste into Jitsi is these two text blocks combined with a “/” between them, like so:
rtmp://peertube.linuxrocks.online:1935/live/8b940f96-c46d-46aa-81a0-701de3c43c8f
Live Stage + Social Event Room: Jitsi
We used the free and open source hosted Jitsi Meet video conferencing platform for our “live stage.” We created a Jitsi meeting room with a custom URL at https://meet.jit.si and only shared this URL with speakers and meeting organizers.
We configured the meeting to have a lobby (this is available in meeting settings once you join your newly-created meeting room) so speakers could join a few minutes before their talk was on without fear of interrupting the talk before theirs. (Our host volunteers let them in when the talk before was done.) Another option is to add a password to the room. We got by just by having a lobby configured. It did seem, upon testing, that moderation status in the room isn’t persistent: if you are a moderator and leave the room, it appeared from our testing that you lose your moderator status and moderation settings such as the lobby setup. So I kept our Jitsi room open and active for the duration of the conference by leaving it open on my computer. (Your mileage may vary on this aspect!)
Jitsi has a built-in live streaming option, where you can post a URL to a video service and it will stream your video to that service. We had confidence in this solution, because it is what we used to host and livestream weekly Fedora Design Team meetings. For the Creative Freedom Summit, we connected our Jitsi Live Stage (for speakers and hosts) to a channel we set up on the Linux Rocks PeerTube.
Jitsi lets speakers share their screens to drive their own slides or live demos.
Live Streaming Jitsi to PeerTube
1. Join the meeting and click the “…” icon next to the red hangup button, at the bottom of the screen.

2. Select “Start live stream” from the menu that pops up.

3. Copy/paste the PeerTube URL+key text

4. Listen for your Jitsi Robot friend
A feminine voice will come on in a few seconds or so to tell you “Live streaming is on.” Once she sounds, smile! You’re live streaming
5. Stop the Live Stream
This will stop the PeerTube URL you set up from working. So you’ll have to repeat these steps again to start things back up.
Jitsi Tips
Managing Recordings via turning the Jitsi stream on and off
One of the things we learned during the conference was that it is better to turn the Jitsi stream off between talks, so you will have one raw recording file posted to PeerTube per talk. We were letting it run as long as it would the first day, so some recordings have multiple talks in the same video, which made using the instant replay function for folks trying to catch up a little bit harder. They needed to seek inside the video to find the talk of interest to watch, or wait for the edited version of the talk to be posted days or weeks later.
Preventing audio feedback
Another issue we figured out live during the event that never cropped up during our dry run tests was audio feedback loops. These were entirely my fault (sorry, to everyone who attended!) What happened is that I was setting up the Jitsi / PeerTube links and monitoring the streams as well as helping host and emcee the event. Even though I knew that once we went live I needed to mute any PeerTube browser tabs I had open, I either had more PeerTube tabs open than I thought and missed one, or the live stream would autostart in my Element client (which I had open to monitor the chat) and I didn’t have an easy way to mute Element. You’ll see in some of the speaker intros I made, I knew I had about 30 seconds before the audio feedback would start, so I gave very rushed/hurried intros!
I think there’s a couple simpler ways you could approach avoiding this situation:
- If possible, make sure your host / emcee is not also the person setting up / monitoring the streams and chat. (Not always possible depending on how many volunteers you have at any given time.)
- If possible, monitor the streams on one computer, and emcee from another. This way, you have one mute button to hit on the computer you’re using for monitoring, and it simplifies your hosting experience and the other.
This is something worth practicing and refining ahead of time.
Backstage: Element

We set up a “Backstage” invite-only chat room a week or so before the conference started and invited all of our speakers to it. This helped us ensure a couple of things:
- Our speakers were onboarded to Element/Matrix well before the event’s start and had the opportnuity to get help signing up if they had any issues (nobody did)
- We started a live communication channel across all speakers in advance enough of the event that we could send announcements / updates pretty easily.
The channel served as a very nice place for the duration of the event to coordinate and help handle transitions between speakers, give heads up about whether or not the schedule was running late, and in one instance quickly reschedule a talk when one of our speakers had an emergency and couldn’t make the original scheduled time.
We also set up a room for hosts, but in our case it ended up being extraneous: we just used the backstage channel to coordinate. We found 2 channels was easy to monitor but three was just too much to be convenient.
Announcements and Q&A: Etherpad / Hackmd.io

We set up a pinned widget in our main Element channel that had some general information about the event, including the daily schedule, code of conduct, etc. We also had a section per talk of the day for attendees to drop questions for Q&A, which the host present in Jitsi with the speaker live read out loud for the speaker.
We found over the first day or two that some attendees were having issues with the Etherpad widget not loading, so we switched to an embedded hackmd.io document pinned to the channel as a widget, and that seemed to work a little better. We’re not 100% sure what was going on with the widget loading issues, but we were able to post a link to the raw (non-embedded) link as well in the channel topic so folks were able to get around any issues accessing it via the widget.
Integrated and Centralized Conference Experience

Matrix via Fedora’s Element server was the key single place to go to attend conference. Matrix chat rooms in Element have a widget system that allows you to embed websites into the chat room as part of the experience, and that functionality was important for having our Matrix chat room serve as the central place to attend.
We embedded the PeerTube livestream right into the channel – you can see it in the screenshot above in the upper left. Once the conference was over, we were able to share a playlist of the unedited video replays playlist, and now that our volunteer project for editing the videos is complete, the channel instead has the playlist of edited talks in order.
As discussed in the previous section, we embedded a hackmd.io note in the upper right corner, and used that to post the day’s schedule, post announcements, and also had an area for Q&A right in the pad. I really had wanted to set up a Matrix bot to handle Q&A, but I struggled to get one up and running. This might make for a cool project for next year, though.
Chat during the conference occured right in the main chat under these widgets.
There are a couple considerations to make when using a Matrix / Element chat room as the central place for an online conference such as this:
- The optimal experience is going to be in the Element desktop client or in a web browser on a desktop system. While you can view the widgets in the Element mobile client (although some attendees struggled to discover this, the UI is less-than-obvious), it is the most convenient to use Element on a desktop. Other Matrix clients may not be able to view the widgets.
- Attendees can easily DIY their own experience piecemeal if desired. For users not using the Element client to attend the conference, they reported not having any issues joining in on the chat and viewing the PeerTube livestream URL directly. We shared the livestream URL and the hackmd URL in the channel topic, which made this accessible to folks who preferred to not run Element.
Website

Ryan Gorley developed the Creative Freedom Summit website using WordPress. It is hosted by WPengine and is a one-pager that includes the conference schedule embedded from sched.org.
Post-event
Post-event survey
We used the open source survey tool LimeSurvey and sent it out within a week or two to attendees via the Element Chat channel as well as via our PeerTube video channel to learn more about how we did handling the event. The organizers of the event continue to meet post-event on a regular basis and one of the things we focused on those post-event meetings was developing the questions for the survey in a shared hackmd.io document. Some of the things we learned from the event that might be of interest to you in planning your own open source powered online conference:
- By far, most event attendees learned about the event from Mastodon and Twitter (together covering 70% of respondents.)
- 33% of attendees used the Element desktop app to attend, and 30% of attendees used the Element Chat web app. So roughly 63% of attendees used the integrated Matrix / Element experience, and the rest watched directly on PeerTube or watched replays after.
- 35% of attendees indicated they made connections with other creatives at the event via the chat, so the chat experience is pretty important to events if part of your goal is enabling networking and connections.
Captioning
During the event, we received very positive feedback from attendees who particularly appreciated when some of the talks were live captioned by another attendee in the chat and wished out loud for live captioning for better accessibility. While the stack we’ve outlined here did not include live captioning, there are open source solutions for this. One such tool is called Live Captions and was covered by Seth Kenlon in an opensource.com article “Open source video captioning on Linux.” While this tool is meant for the attendee consuming the video content locally, we could potentially have a host for the conference running this tool and sharing it to the livestream in Jitsi, perhaps via the use of the open source broadcasting tool OBS so everyone watching the live stream could benefit from the captions.
In editing the videos post-event, however, we also discovered a tool built into Kdenlive, our open source video editor of choice, that generates and automatically places subtitles in the videos. There are some basic instructions on how to do this in the Kdenlive manual, but Fedora Design Team member Kyle Conway who helped with the post-event video editing put together a comprehensive tutorial (including video instruction) on how to automatically generate and add subtitles to videos in Kdenlive, and it is well worth the read and watch if you are interested in this feature.
Video editing volunteer effort
As soon as the event was over. we rallied a group of volunteers from the conference Element channel to work together on editing the videos down, including title cards and intro/outro music and general cleanup. (Some of our automatic replay recordings were split across two files or combined in one file with multiple other talks and needed to be reassembled or cropped down.)
We used a GitLab epic to organize the work, with an FAQ and call for volunteer help organized by skillset, with issues attached for each video needed. We had a series of custom labels we would set on each video so it was clear what state the video was in and what kind of help was needed. All of the videos at this point have been edited; some need descriptions written for their description area on the Creative Freedom Summit channel, and many have the auto-generated subtitles that have not been edited for spelling mistakes and other corrections that are typically needed from auto-generated text.

The way we handled passing the videos around – since the files could be quite large – is that we had volunteers download the raw video from the unedited recording on the main PeerTube channel for the Creative Freedom Summit. When they had an edited video ready to share, we had a private PeerTube account they could upload the edited videos to, and admins with access to the main channel’s account periodically grabbed videos from the private account and uploaded them into the main account. Note that PeerTube doesn’t have a system where multiple accounts have access to the same channel, so we had to engage in a bit of password sharing which can be a bit nerve-wracking, so we felt this was a reasonable compromise to limit how many people had the main password but still enable volunteers to be able to submit edited videos without too much hassle.
Ready to give it a try?
I hope this comprehensive description of how we ran the Creative Freedom Summit conference using an open source stack of tools inspires you to try it for your open source conference. Let us know how it goes and feel free to reach out if you have questions or suggestions for improvement! Our channel is at:
https://matrix.to/#/#creativefreedom:fedora.im






 There’s a ton of possibilities for how you can apply this technique, so let your imagination soar.
There’s a ton of possibilities for how you can apply this technique, so let your imagination soar.




















 </figure>
</figure>
 </figure>
</figure>























































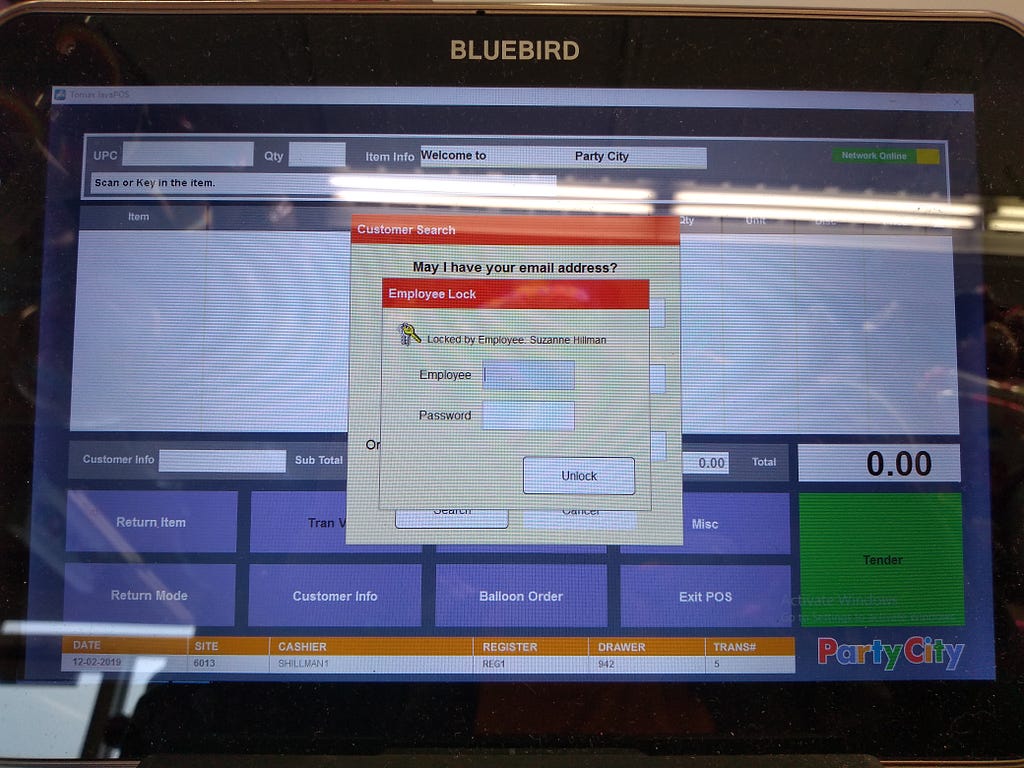 <figcaption>View of a logged-in, but locked, register</figcaption></figure>
<figcaption>View of a logged-in, but locked, register</figcaption></figure> <figcaption>My pointer finger compared size with the touch target size of the login text entry field</figcaption></figure>
<figcaption>My pointer finger compared size with the touch target size of the login text entry field</figcaption></figure>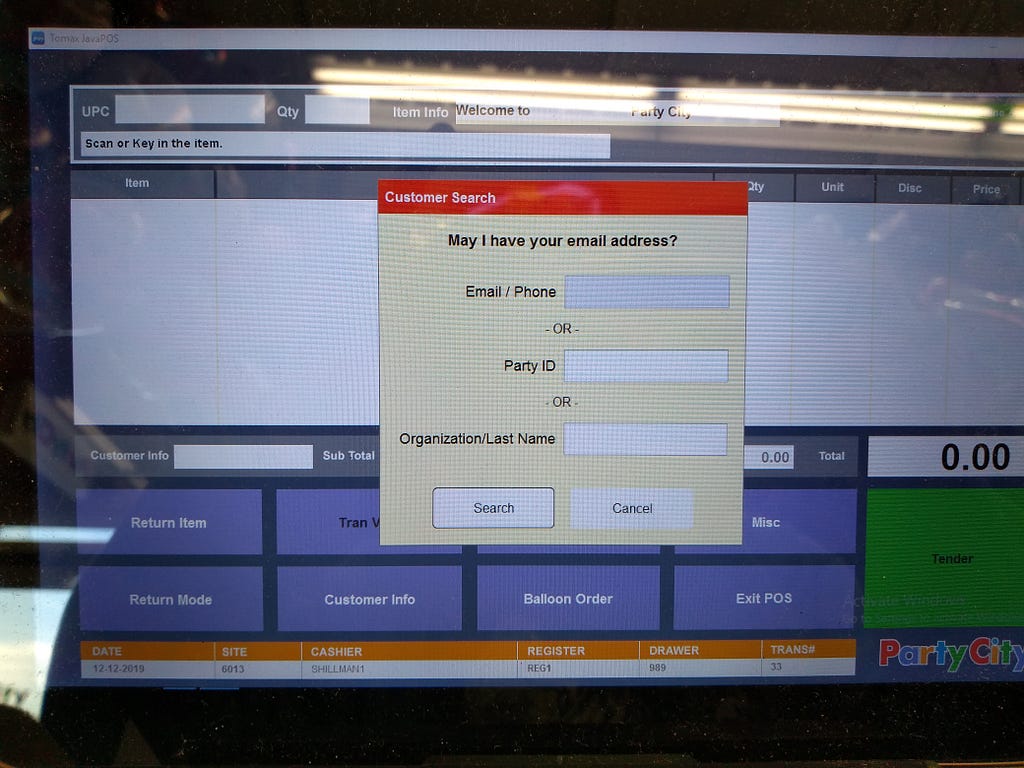 <figcaption>View of a logged-in register before the start of a transaction</figcaption></figure>
<figcaption>View of a logged-in register before the start of a transaction</figcaption></figure> <figcaption>A register once one has scanned an item (in this case, candy).</figcaption></figure>
<figcaption>A register once one has scanned an item (in this case, candy).</figcaption></figure>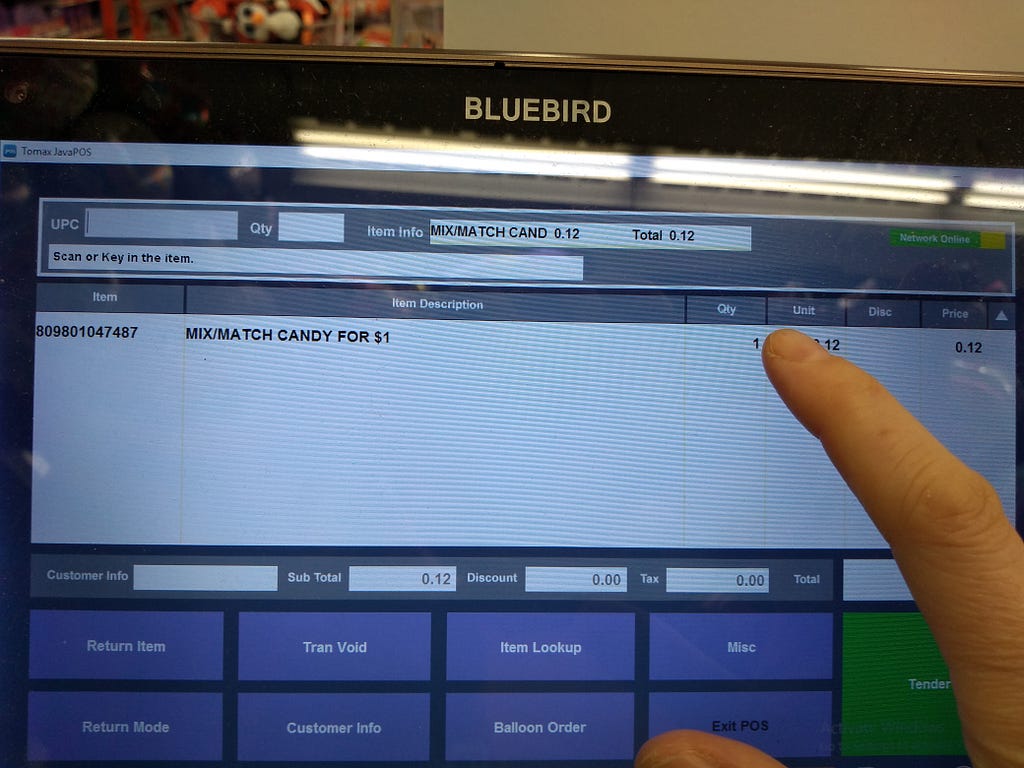 <figcaption>Moving to touch the quantity field for adjustments</figcaption></figure>
<figcaption>Moving to touch the quantity field for adjustments</figcaption></figure>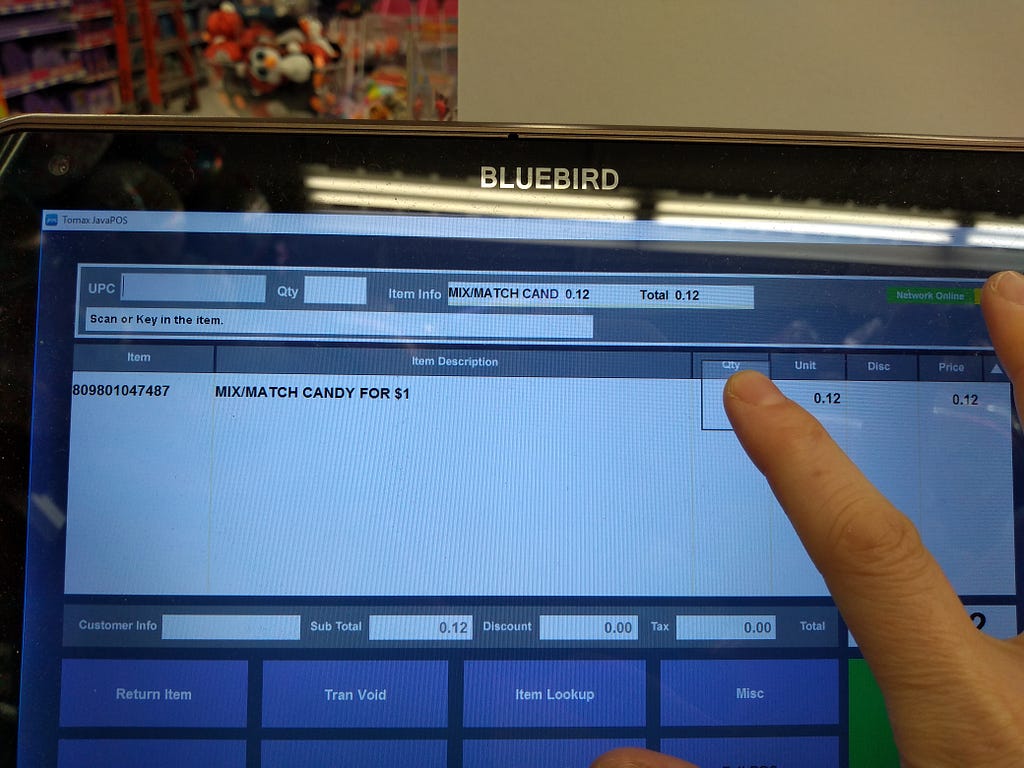 <figcaption>My finger actually contacting the area that I was aiming for.</figcaption></figure>
<figcaption>My finger actually contacting the area that I was aiming for.</figcaption></figure>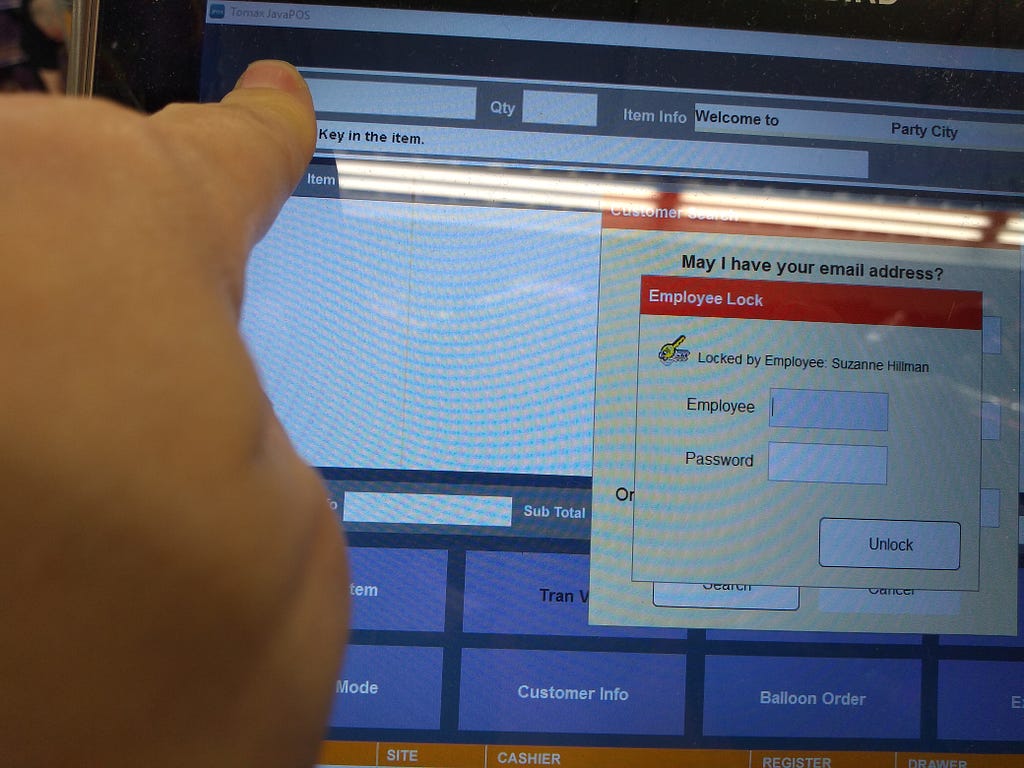 <figcaption>My pointer finger size compared to the UPC field of the register</figcaption></figure>
<figcaption>My pointer finger size compared to the UPC field of the register</figcaption></figure>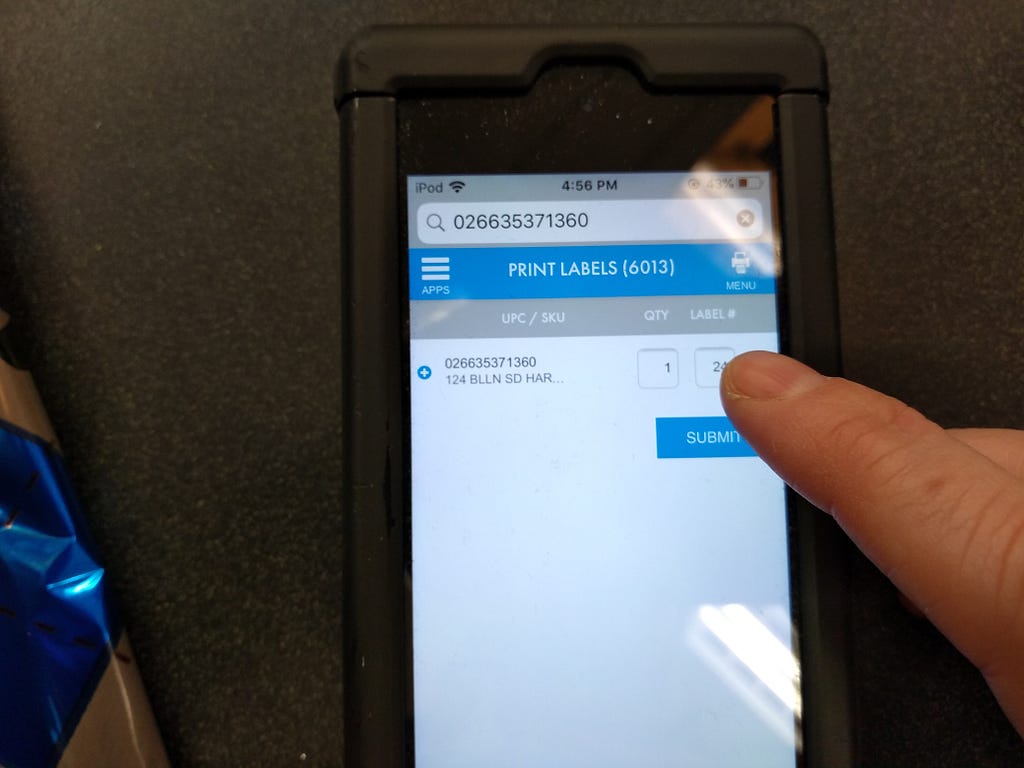 <figcaption>The label size was a tiny touch target! Also, it was called “label #” for some reason.</figcaption></figure>
<figcaption>The label size was a tiny touch target! Also, it was called “label #” for some reason.</figcaption></figure> <figcaption>Hitting the label field was really really difficult.</figcaption></figure>
<figcaption>Hitting the label field was really really difficult.</figcaption></figure> <figcaption>Relative size of the text on the view screen from the location that one was typically standing in to access the keyboard and cash drawer.</figcaption></figure>
<figcaption>Relative size of the text on the view screen from the location that one was typically standing in to access the keyboard and cash drawer.</figcaption></figure>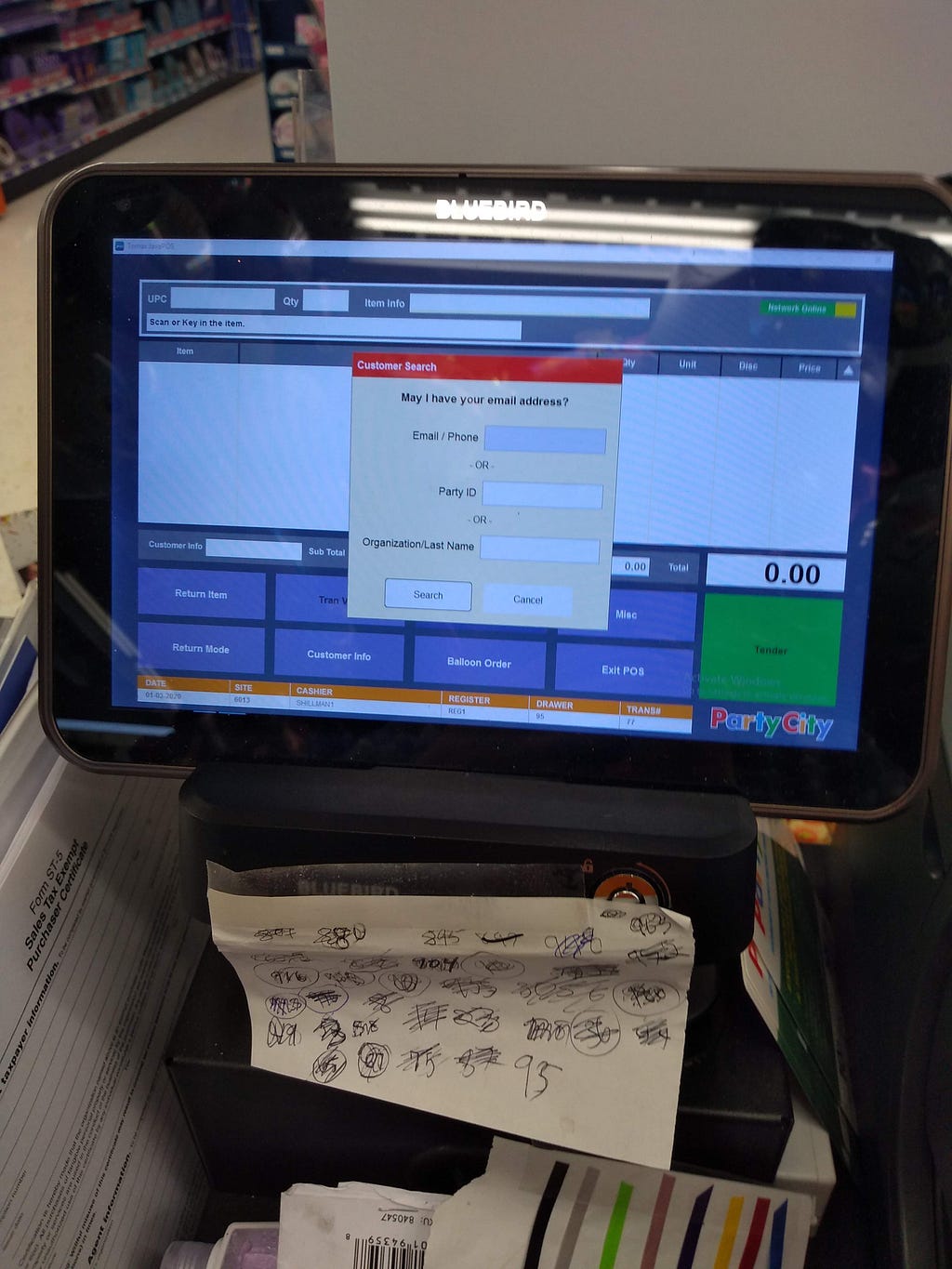 <figcaption>Distance at which one tended to need to stand to easily read the text on the screen.</figcaption></figure>
<figcaption>Distance at which one tended to need to stand to easily read the text on the screen.</figcaption></figure>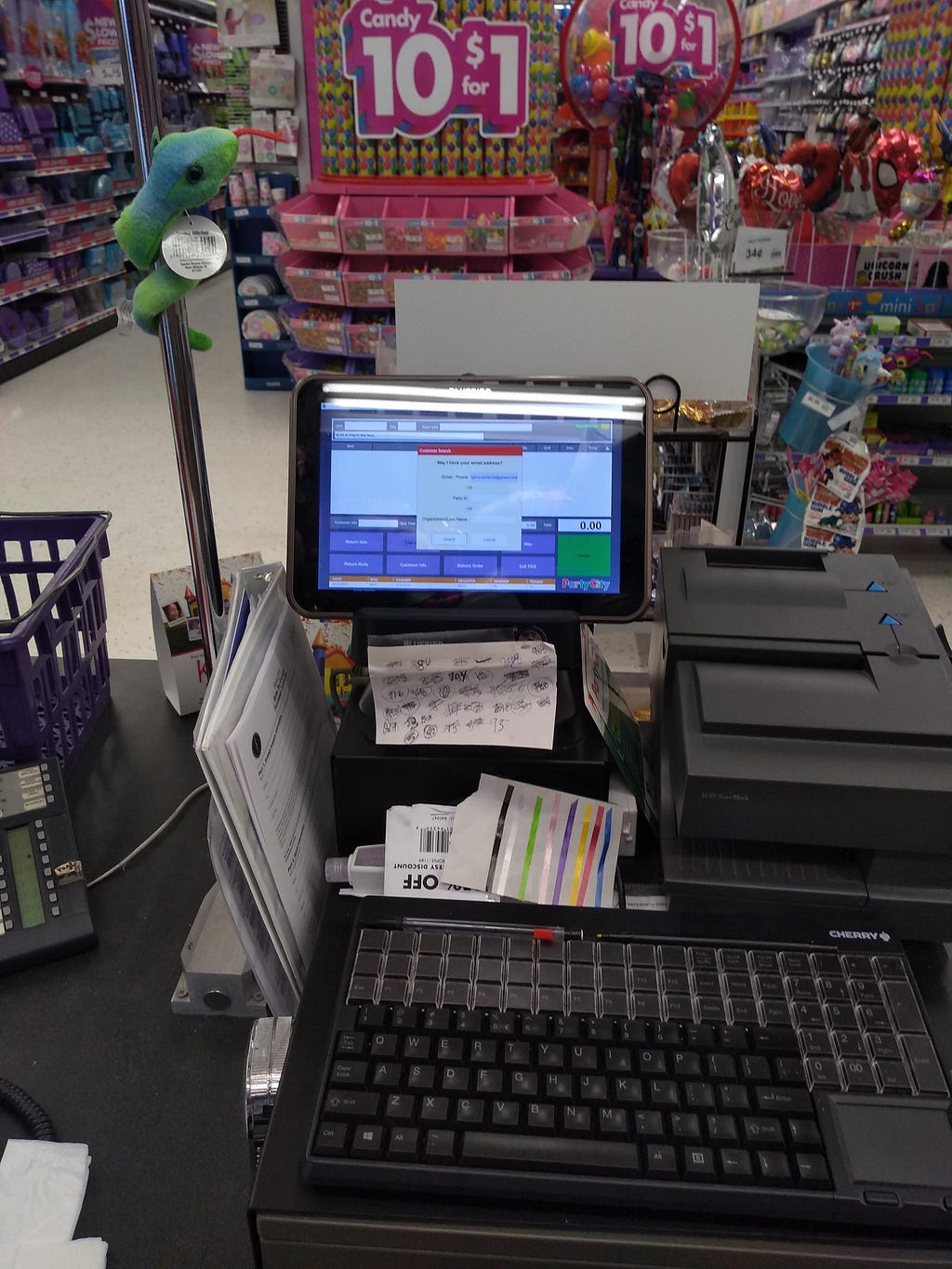 <figcaption>Again, approximate typical place to stand. This time, showing an email address.</figcaption></figure>
<figcaption>Again, approximate typical place to stand. This time, showing an email address.</figcaption></figure>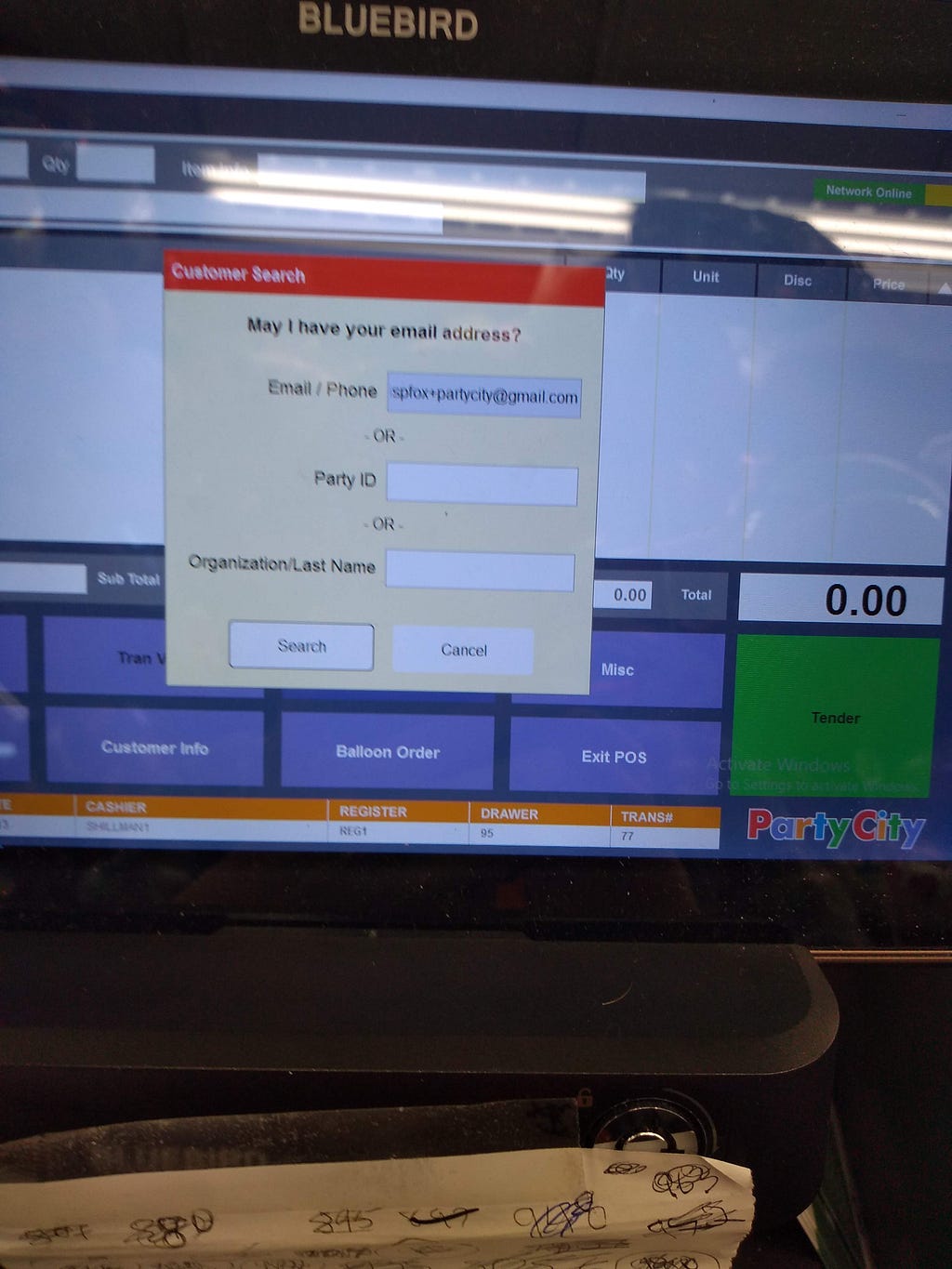 <figcaption>Slightly blurry, but this was a decent distance at which to check an email address for errors</figcaption></figure>
<figcaption>Slightly blurry, but this was a decent distance at which to check an email address for errors</figcaption></figure>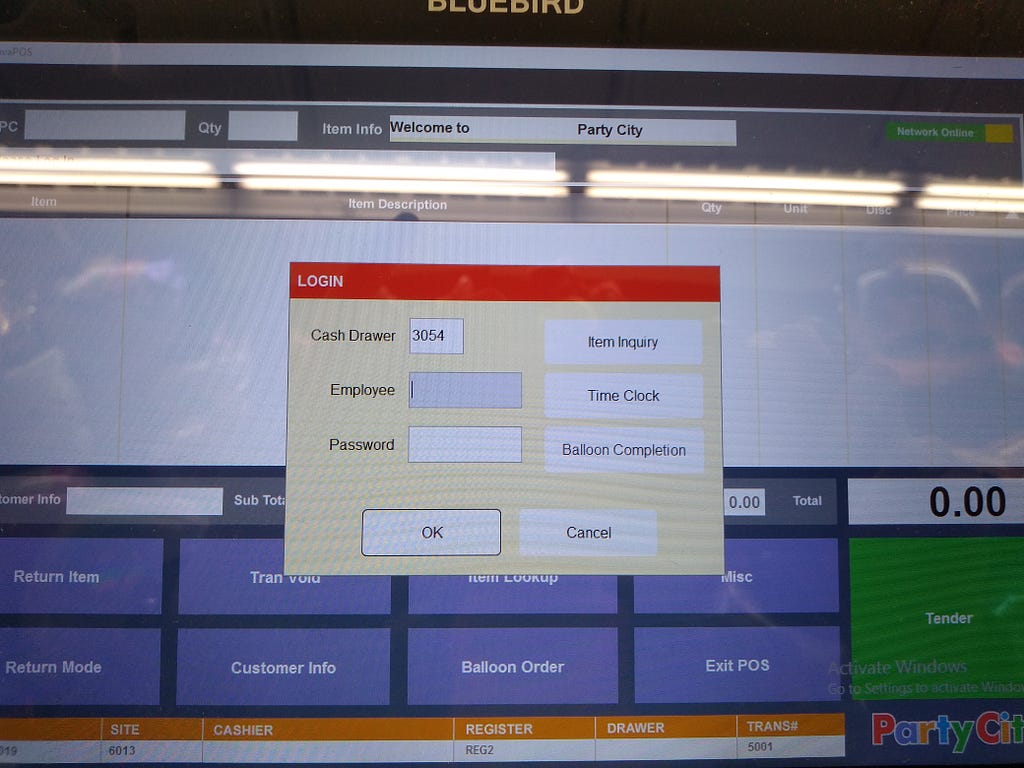 <figcaption>A register screen that no one has logged into.</figcaption></figure>
<figcaption>A register screen that no one has logged into.</figcaption></figure> <figcaption>The interface for entering emails and phone numbers</figcaption></figure>
<figcaption>The interface for entering emails and phone numbers</figcaption></figure>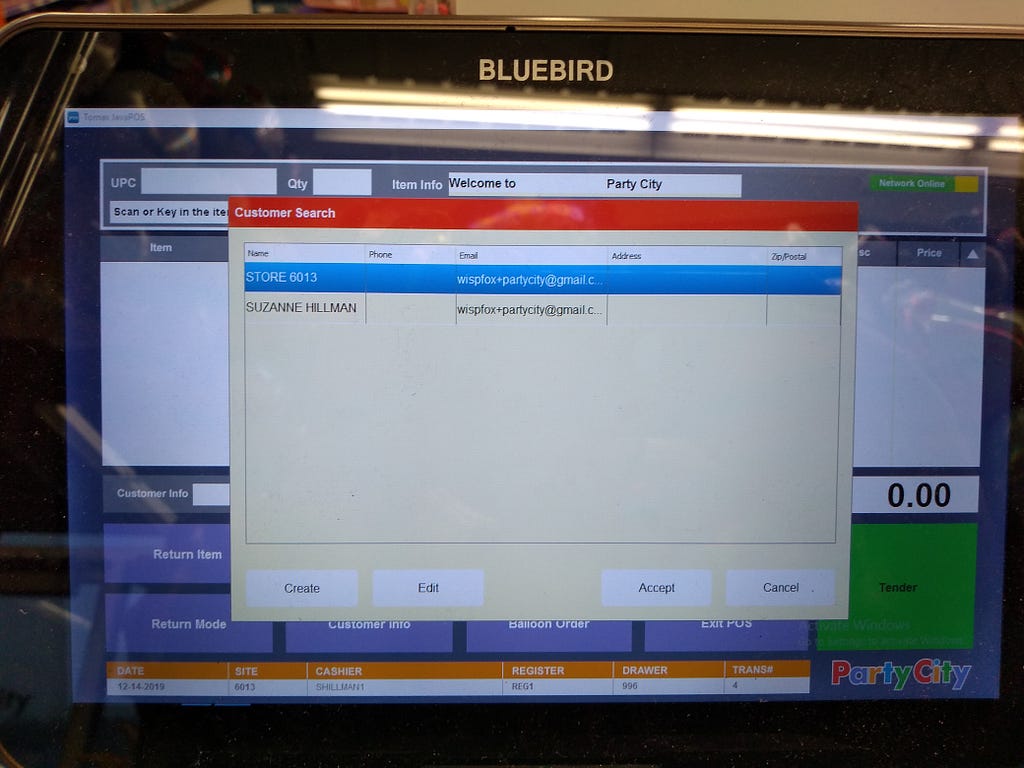 <figcaption>After hitting search, you may have had options to choose from</figcaption></figure>
<figcaption>After hitting search, you may have had options to choose from</figcaption></figure>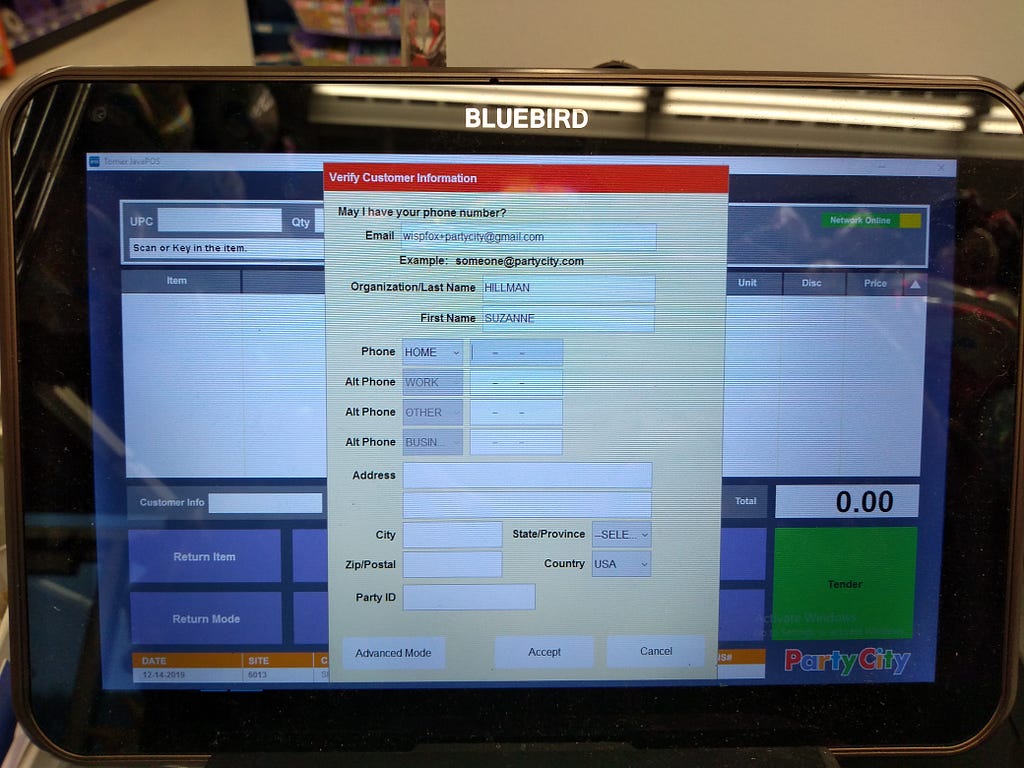 <figcaption>Why are you making me enter in more information? I have a name and email!</figcaption></figure>
<figcaption>Why are you making me enter in more information? I have a name and email!</figcaption></figure> <figcaption>You should know the state or province! There is a zip code.</figcaption></figure>
<figcaption>You should know the state or province! There is a zip code.</figcaption></figure>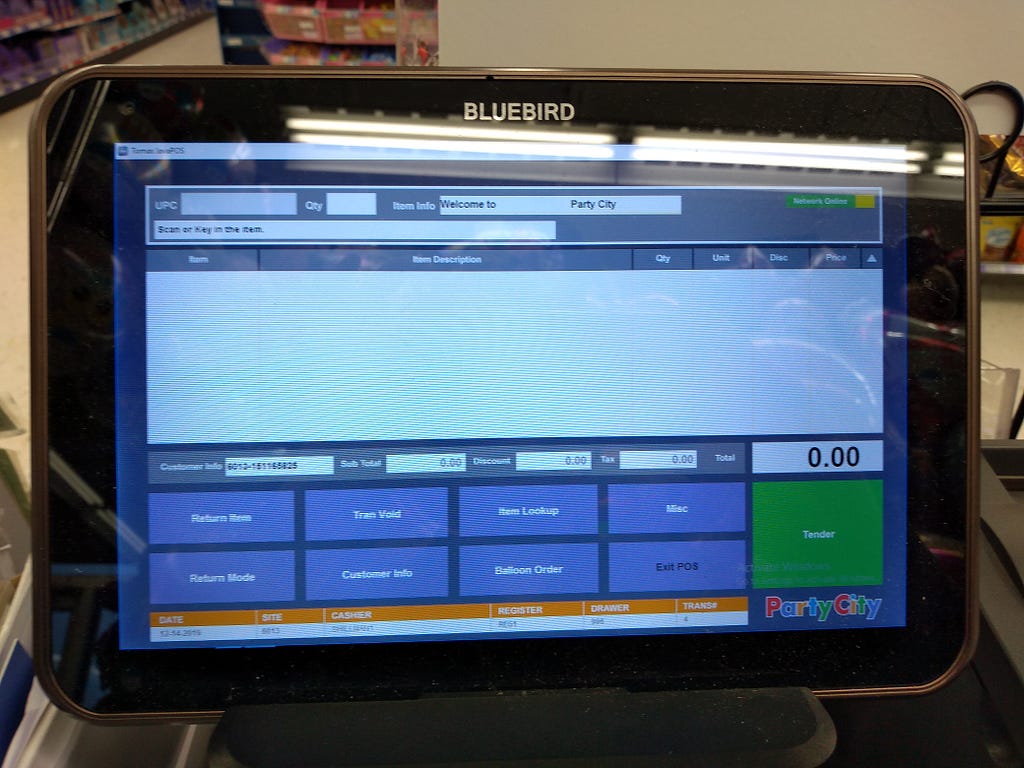 <figcaption>Yay, you can scan things! And it knows who the customer is (based on the customer info field).</figcaption></figure>
<figcaption>Yay, you can scan things! And it knows who the customer is (based on the customer info field).</figcaption></figure>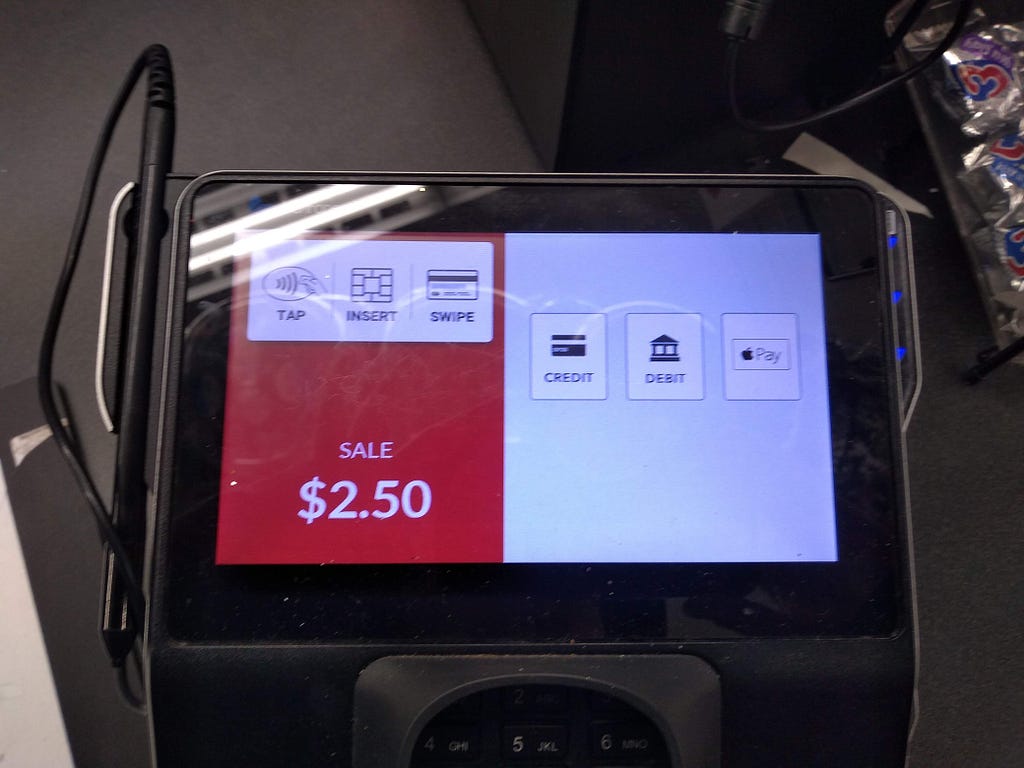 <figcaption>This looks like it needs you to select the type of payment, but it will auto-detect in the vast majority of cases.</figcaption></figure>
<figcaption>This looks like it needs you to select the type of payment, but it will auto-detect in the vast majority of cases.</figcaption></figure> <figcaption>This screen is entirely undifferentiated and unorganized</figcaption></figure>
<figcaption>This screen is entirely undifferentiated and unorganized</figcaption></figure>



















































 )
)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}